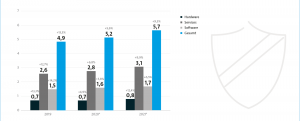
Fehlervermeidung bei manueller Dateneingabe
 Exklusiv für Abonnenten
Exklusiv für AbonnentenIdeales Zusammenspiel
Als ideal ist letztlich das Zusammenspiel zwischen regel- und datenbasierter Eingabehilfe zu betrachten. Das zeigt sich unter anderem bei der Dynamisierung von Formularen: Soll ein System kontextabhängig irrelevante Eingabefelder automatisch ausblenden, sind strikte Regeln sinnvoll. Für ihren Einsatz sprechen nicht zuletzt auch feste Abhängigkeiten zwischen Attributen. Bei einem Handelsvertrag hängen die auswählbaren Positionen z.B. immer davon ab, ob es sich um Kauf oder Verkauf handelt.
Nicht vertauschen
Auto-Vervollständigung allein sichert die Richtigkeit eines Datensatzes aber noch nicht vollumfänglich ab. Eine weitergehende Prüfung ist notwendig, um auszuschließen, dass z.B. Einheiten verwechselt oder Zellen vertauscht und fehlerhaft in eine Datenbank übertragen wurden. Ein Praxisbeispiel: Wird bei der Erfassung eines Verkaufsvertrags bei der Eingabe der vereinbarten Menge anstatt Kilogramm Tonnen ausgewählt und das Komma bei der Preisangabe um eine Stelle nach vorn verrutscht, wird ohne Datenvalidierung eine viel zu große Menge (Faktor 1.000) zu einem viel zu geringen Preis (Faktor 0,1) verkauft.
Einige Unternehmen setzen aus diesem Grund auf Kontrollstellen, die vor der Übertragung in eine Datenbank Formulare auf ihre Richtigkeit prüfen. Dieser Vorgang nimmt viel Zeit in Anspruch und ist auch selbst fehleranfällig. Für die meisten Unternehmen ist es wirtschaftlich ohnehin nicht realisierbar. Daher kommt ein vorgeschalteter Filter zum Einsatz. Das Ziel: Die Prüfer sollen sich auf Fehler mit großen Folgewirkungen konzentrieren. Die wiederum vorrangig regelbasierten, pflegeaufwändigen Systeme suchen auf Basis von Schwellenwertprüfungen nach fest definierten Anomalien in den Eingabedatensätzen. Überschreitet z.B. ein eingetragenes Gewicht den Schwellenwert von einer Tonne, überprüft die Kontrollstelle die vorliegenden Eingabedaten. Problematisch wird es jedoch, wenn Prüfregeln fehlen oder bezogen auf ihre Abhängigkeiten unvollständig sind.
Fehlt im geschilderten Beispiel eine Prüfregel für das Mengen-Preis-Verhältnis, werden mehrere hundert Datensätze knapp unter einer Tonne mit zu geringen Preisen an der Kontrollstelle vorbei in die Datenbank übertragen. Die Lösung für eine effiziente, ergänzende Datenvalidierung liegt auch hier in dem beschriebenen Mechanismus. Auf der breiten Basis historisierter Daten kann das KI-System selbsttätig Anomalien in den prozessspezifischen Strukturen der gesamten Datensätze erkennen und passt sich kontinuierlich an die aktuellen Gegebenheiten an. Das Ergebnis: Das System leitet für die manuelle Prüfung ausschließlich Dateneingaben mit entsprechenden Anomalien weiter, ohne auf starre Regeln oder Eigenschaften festgelegt zu sein.
Zeit sparen
Die funktionale Komplexität von Business-IT-Lösungen wird zukünftig weiter zunehmen, auch wenn die Entwicklung von modularen Architekturen zu offeneren und agileren Strukturen führt. Umso wichtiger sind schnelle und korrekte Dateneingaben – unterstützt und geprüft durch intelligente Logiken. Dafür eignen sich integrierte KI-Systeme. Sie lernen die notwendigen Muster und Strukturen selbsttätig auf Basis historisierter Daten und passen diese automatisiert und kontinuierlich an. Dadurch lässt sich sowohl die Anwenderfreundlichkeit als auch die Datenkonsistenz messbar erhöhen. Das spart Zeit, Aufwände und Kosten.
Das könnte Sie auch interessieren

Für das aktuelle Allianz Risk Barometer wurden 3000 Risikoexperten befragt. Das Ergebnis: Als größte Risiken nennen die Teilnehmer Datenpannen, Angriffe auf kritische Infrastruktur oder Vermögenswerte und vermehrte Ransomware-Attacken. Anders als weltweit schafft es der Fachkräftemangel in Deutschland auf Platz 4.‣ weiterlesen

In Potsdam laufen die Vorbereitungen für eine vollständig digitale Universität. Die beiden Initiatoren Mike Friedrichsen und Christoph Meinel wollen damit dem IT-Fachkräftemangel entgegenwirken.‣ weiterlesen
@Grundschrift_NH:Nvidias Omniverse lässt sich künftig über T-Systems beziehen. Die Plattform der Grafik-Spezialisten ermöglicht es, komplexe 3D-Pipelines und Universal Scene Description (OpenUSD)-Anwendungen für Industrieanwendungen zu entwickeln und anzubinden. So können Unternehmen ihre 3D-Werkzeuge und -Daten mit dem Open-USD-Standard vereinheitlichen, um Teams über ihre PCs in bis zu fotorealistischen Visualisierungen und Simulationen zusammenzubringen. ‣ weiterlesen
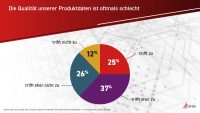
Sechs von zehn Unternehmen sind mit der Qualität ihrer Produktdaten unzufrieden. Das zeigt eine europaweite Befragung des Softwareherstellers Aras unter mehr als 440 Entscheidern. Zudem ergab die Untersuchung, dass Informationen, die eigentlich abteilungsübergreifend zugänglich sein sollten, oft ungenutzt in abgeschotteten Unternehmensbereichen liegen.‣ weiterlesen

Der Anteil der Unternehmen, die KI einsetzen, ist binnen eines Jahres von 9 auf 15 Prozent gestiegen. Das ist das Ergebnis einer Bitkom-Befragung unter 605 Unternehmen. Zwei Drittel von ihnen sehen KI als wichtigste Zukunftstechnologie.‣ weiterlesen

Derzeit erleben wir multiple Krisen - neben zunehmenden geopolitischen Spannungen entwickelt sich die Erderwärmung zu einer immer größeren Herausforderung. Das Umweltbundesamt rechnet bis Ende des 21. Jahrhunderts mit einer Erhöhung der mittleren Erdtemperatur um bis zu 5,7 Grad Celsius, sofern nicht kurzfristig eine massive Reduktion der CO2-Emissionen erfolgt. Wie der CO2-Fußabdruck dabei unterstützen kann, beschreibt ein Beitrag des Beratungsunternehmens Aflexio.‣ weiterlesen
Mit bestehenden Geothermiebohrungen im Oberrheingraben könnte zuverlässig Lithium gefördert werden. Das zeigen aktuelle Datenanalysen von Forschenden des Karlsruher Instituts für Technologie (KIT). Frisches Tiefenwasser sorgt über mehrere Jahrzehnte für Nachschub. ‣ weiterlesen
Mit einem messdatengestützten Retrofit-System können ältere Windkraftanlagen länger laufen. Im von Bachmann Monitoring und P. E. Concepts entwickelten System fließen erfasste Last- und Eigenfrequenzdaten in die Lebensdauer-Berechnung von Komponenten ein. Anhand dieser Daten lässt sich eine realistischere Restnutzungsdauer errechnen, um den rentablen Weiterbetrieb zu ermöglichen. ‣ weiterlesen
INDUSTRIE 4.0 & IIoT-MAGAZIN Leseprobe

Zeitschrift für Industrie 4.0, Internet of Things & Digitale Transformation


Hannover Messe 2024: Die Industrie auf dem Weg zu mehr Nachhaltigkeit
Vom 22. bis zum 26. April wird Hannover zum Schaufenster für die Industrie. Neben künstlicher Intelligenz sollen insbesondere Produkte und Services für eine nachhaltigere Industrie im Fokus stehen.‣ weiterlesen

Deutsche Industrie sieht Data Act als Chance
Eine Umfrage von Hewlett Packard Enterprise (HPE) unter 400 Führungskräften in Industrie-Unternehmen in Deutschland zeigt, dass zwei Drittel der Befragten den Data Act als Chance wahrnehmen. Der Data Act stieß unter anderem bei Branchenverbänden auf Kritik.‣ weiterlesen

Unternehmen sehen Cyber-Angriffe als größte Bedrohung der digitalen Transformation
Deutsche Unternehmen nehmen eine zunehmende Bedrohung durch Cyber-Angriffe wahr. Das zeigt eine aktuelle Umfrage vom Markt- und Meinungsforschungsinstitut YouGov im Auftrag von 1&1 Versatel, an der mehr als 1.000 Unternehmensentscheider teilnahmen.‣ weiterlesen

Carbon Management: Wegbereiter für eine klimaneutrale Zukunft
Carbon Management-Technologien stehen im Fokus, um CO2-Emissionen zu reduzieren und zu managen. Die Rolle des Maschinenbaus und mögliche Entwicklungspfade betrachtet eine neue Studie des VDMA Competence Center Future Business.‣ weiterlesen
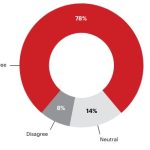
Produktivitätssteigerungen von bis zu 50 Prozent durch KI
Laut einer Studie der Unternehmensberatung Bain & Company könnten Unternehmen ihre Produktivität durch digitale Tools, Industrie 4.0-Technologien und Nachhaltigkeitsmaßnahmen steigern. Deren Implementierung von folgt oft jedoch keiner konzertierten Strategie.‣ weiterlesen