Exklusiv für Abonnenten
Exklusiv für AbonnentenFehlervermeidung bei manueller Dateneingabe
KI-gestützte Autovervollständigung und Datenvalidierung
Die Qualität der Daten ist entscheidend für die Effizienz operativer Prozesse und für die Zuverlässigkeit von Berichten. Manuelle Dateneingabe birgt jedoch hohes Fehlerpotenzial und Vielfach bewährte, regelbasierte Eingabehilfen und Datenvalidierungen stoßen im Hinblick auf eine zunehmende Dynamisierung von Geschäftsprozessdaten oftmals an ihre Grenzen. Die Integration KI-gestützter, datenbasierter Lösungsansätze schafft Abhilfe.

(Bild: PSi FLS Fuzzy Logic & Neuro Systems GmbH/©rawf8/shutterstock.com)
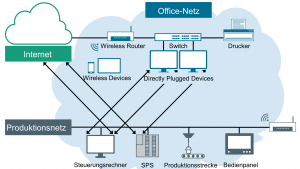
Branchenübergreifend ist die Erfassung von Daten über Eingabemasken ein zentraler Bestandteil vieler Softwarelösungen, z.B. in ERP- und anderen Verwaltungssystemen. Typisch für industrielle Anwendungen ist dabei unter anderem die große Anzahl verfügbarer Eingabefelder sowie Freiheiten bei der manuellen Dateneingabe. Die händische Bearbeitung kostet Zeit. Das kann dazu führen, dass Anwender vermehrt optionale Felder nicht oder nur teilweise ausfüllen. Hinzu kommt, dass durch die Freiheiten bei der Eingabe – z.B. die Verwendung von Abkürzungen – verschiedene Nutzer für die gleiche Semantik unterschiedliche Schreibweisen verwenden. Die daraus resultierenden Prozessverzögerungen, Dateninkonsistenzen und -fehler führen nicht nur zu einer signifikanten Verschlechterung des Berichtwesens. Da mit der Qualität der eingegebenen Daten sowohl die Effizienz des Prozesses selbst als auch seiner Nachfolger steht und fällt, können sie Folgefehler nach sich ziehen, die wiederum Nacharbeiten erfordern.
Eingabehilfen als Mittel der Wahl?
Eingabehilfen sollen dieses Problem lösen. Die bisherigen Ansätze können dies aber nur teilweise und können vor allem bei semantisch variierenden, multiplen Abhängigkeiten in den Daten an ihre Grenzen stoßen. Die Mehrheit der bekannten Eingabehilfen basiert auf fest definierten Regeln, die aus der kontextabhängigen Syntax und Semantik abgeleitet sind. Der Vorteil: Sie bilden die jeweiligen Geschäftsprozesse präzise ab. Als solche sind sie eine gute Lösung für gut strukturierte und über die Zeit beständige Vorgänge, etwa bei klar definierten Datenabhängigkeiten oder eingeschränkter Auswahl per Drop-Down.
Ihr Nachteil: Für die Eingabeüberprüfung bedienen sie sich aufwändiger Logiken. Je detaillierter die Abbildung von Prozessen also ist, desto komplexer ist das Regelsystem. Hinzu kommt, dass Änderungen immer Anpassungen der Codebasis erfordern. Ungeeignet sind regelbasierte Lösungsansätze in diesem Kontext für die Eingabeunterstützung von Daten, die in multiplen Abhängigkeiten stehen und teilweise semantisch variieren. Das trifft z.B. auf die Datenerfassung in Bestell- und Lieferprozessen zu und damit auf einen wachsenden Anteil relevanter Einsatzszenarien.
Autovervollständigung per KI
Abhilfe kann eine KI-gestützte, datenbasierte Auto-Vervollständigung bieten. Dieser Lösungsansatz macht sich die Tatsache zunutze, dass für nahezu alle Geschäftsabläufe mit einem Datenerfassungsprozess historisierte Daten zur Verfügung stehen. Unter Zuhilfenahme von Qualitativem Labeln und maschinellem Lernen trainieren und aktualisieren KI-Tools wie Deep Qualicision auf dieser Datenbasis kontinuierlich das relevante Nutzerverhalten. Automatisch werden folglich auch neue Daten einbezogen und die Wissensbasis kontinuierlich angepasst. Das KI-System kann so konfiguriert werden, dass es fortwährend typische Eingabemuster aus Vergangenheitsdaten erlernt – und zwar entweder allgemeingültig oder benutzerabhängig. Als Entscheidungsunterstützung für ein solches System dient ein einfaches Präferieren individuell definierbarer Bewertungskennzahlen (Key Performance Indicators, KPI). Dadurch lassen sich Abweichungen von Vorhersagen bewerten und Eingabedatensätze automatisiert validieren.
So kann z.B. eine anormale Abweichung einer Bestellmenge bereits bei der Dateneingabe erkannt werden, die gegebenenfalls bei einem Schwellenwertverfahren durch das Erkennungsraster fallen würde. Das Ergebnis: Das System vervollständigt die Eingabe von Daten automatisch und individuell angepasst an jeden Geschäftsprozess. Damit ist dieser Ansatz auch für die Abbildung der beschriebenen, semantisch variierenden und multipel abhängigen Daten geeignet.
Das könnte Sie auch interessieren

Für das aktuelle Allianz Risk Barometer wurden 3000 Risikoexperten befragt. Das Ergebnis: Als größte Risiken nennen die Teilnehmer Datenpannen, Angriffe auf kritische Infrastruktur oder Vermögenswerte und vermehrte Ransomware-Attacken. Anders als weltweit schafft es der Fachkräftemangel in Deutschland auf Platz 4.‣ weiterlesen

In Potsdam laufen die Vorbereitungen für eine vollständig digitale Universität. Die beiden Initiatoren Mike Friedrichsen und Christoph Meinel wollen damit dem IT-Fachkräftemangel entgegenwirken.‣ weiterlesen
@Grundschrift_NH:Nvidias Omniverse lässt sich künftig über T-Systems beziehen. Die Plattform der Grafik-Spezialisten ermöglicht es, komplexe 3D-Pipelines und Universal Scene Description (OpenUSD)-Anwendungen für Industrieanwendungen zu entwickeln und anzubinden. So können Unternehmen ihre 3D-Werkzeuge und -Daten mit dem Open-USD-Standard vereinheitlichen, um Teams über ihre PCs in bis zu fotorealistischen Visualisierungen und Simulationen zusammenzubringen. ‣ weiterlesen
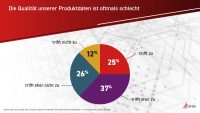
Sechs von zehn Unternehmen sind mit der Qualität ihrer Produktdaten unzufrieden. Das zeigt eine europaweite Befragung des Softwareherstellers Aras unter mehr als 440 Entscheidern. Zudem ergab die Untersuchung, dass Informationen, die eigentlich abteilungsübergreifend zugänglich sein sollten, oft ungenutzt in abgeschotteten Unternehmensbereichen liegen.‣ weiterlesen

Der Anteil der Unternehmen, die KI einsetzen, ist binnen eines Jahres von 9 auf 15 Prozent gestiegen. Das ist das Ergebnis einer Bitkom-Befragung unter 605 Unternehmen. Zwei Drittel von ihnen sehen KI als wichtigste Zukunftstechnologie.‣ weiterlesen

Derzeit erleben wir multiple Krisen - neben zunehmenden geopolitischen Spannungen entwickelt sich die Erderwärmung zu einer immer größeren Herausforderung. Das Umweltbundesamt rechnet bis Ende des 21. Jahrhunderts mit einer Erhöhung der mittleren Erdtemperatur um bis zu 5,7 Grad Celsius, sofern nicht kurzfristig eine massive Reduktion der CO2-Emissionen erfolgt. Wie der CO2-Fußabdruck dabei unterstützen kann, beschreibt ein Beitrag des Beratungsunternehmens Aflexio.‣ weiterlesen
Mit bestehenden Geothermiebohrungen im Oberrheingraben könnte zuverlässig Lithium gefördert werden. Das zeigen aktuelle Datenanalysen von Forschenden des Karlsruher Instituts für Technologie (KIT). Frisches Tiefenwasser sorgt über mehrere Jahrzehnte für Nachschub. ‣ weiterlesen
Mit einem messdatengestützten Retrofit-System können ältere Windkraftanlagen länger laufen. Im von Bachmann Monitoring und P. E. Concepts entwickelten System fließen erfasste Last- und Eigenfrequenzdaten in die Lebensdauer-Berechnung von Komponenten ein. Anhand dieser Daten lässt sich eine realistischere Restnutzungsdauer errechnen, um den rentablen Weiterbetrieb zu ermöglichen. ‣ weiterlesen
In einer Umfrage im Auftrag von Teradata zeigt sich, dass die Mehrheit der 900 Befragten generative KI für nützlich hält. Doch die
Befragten sorgen sich vor voreingenommenen Ergebnissen der KI – und rechnen mehrheitlich mit sinkendem Interesse an GenAI. ‣ weiterlesen
INDUSTRIE 4.0 & IIoT-MAGAZIN Leseprobe

Zeitschrift für Industrie 4.0, Internet of Things & Digitale Transformation


Generative KI in der Fertigung: Der Mehrwert ist oft noch unklar
3 Prozent der großen Industrieunternehmen setzen GenAI bereits großflächig ein, und rund ein Viertel hat erste Pilotprojekte gestartet. Laut einer Untersuchung der Unternehmensberatung McKinsey kann die Mehrheit der Unternehmen den Mehrwert der Technologie für den Unternehmenserfolg bislang aber noch nicht beziffern.‣ weiterlesen

Die Zukunft der Fertigung basiert auf Open Source
Die Industrie arbeitet daran, die Barrieren zwischen IT und OT abzubauen. So können Unternehmen ihre Produktion effizienter und innovativer gestalten und im immer härter werdenden globalen Wettbewerb bestehen. Francis Chow von Red Hat erklärt, welche Rolle Open-Source-Technologien dabei spielen.‣ weiterlesen

Deutsche Hersteller bereiten Smart Manufacturing vor
Für dauerhafte Wettbewerbsfähigkeit müssen deutsche Hersteller angesichts weiterhin drohender Rezession und hoher Energiekosten die nächste Stufe der Digitalisierung erreichen. Die Mehrheit der Unternehmen bereitet sich in diesem Zug auf Smart Manufacturing vor, wie eine von Statista durchgeführte und Avanade beauftragte Studie zeigt.‣ weiterlesen
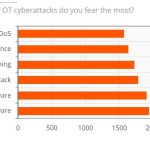
Wie steht es um die OT-Sicherheit?
Ein Bericht von ABI Research und Palo Alto Networks über den Stand der OT-Sicherheit zeigt, dass im vergangenen Jahr eines von vier Industrieunternehmen seinen Betrieb aufgrund eines Cyberangriffs vorübergehend stilllegen musste. Die Komplexität beim Einsatz von OT-Sicherheitslösungen stellt für die Befragten das größte Hindernis dar.‣ weiterlesen

Hannover Messe 2024: Die Industrie auf dem Weg zu mehr Nachhaltigkeit
Vom 22. bis zum 26. April wird Hannover zum Schaufenster für die Industrie. Neben künstlicher Intelligenz sollen insbesondere Produkte und Services für eine nachhaltigere Industrie im Fokus stehen.‣ weiterlesen