Interview mit Kai Schwab von Crosser
“Die zentrale Datenverarbeitung wird wichtiger”
Daten lesen, speichern und weiterleiten – darum geht es beim Thema Edge Analytics. Kai Schwab, Regional Sales Director DACH bei Crosser, erklärt im Gespräch mit dem INDUSTRIE 4.0 & IIoT-MAGAZIN, welche Use Cases dafür prädestiniert sind und warum eine zentrale Datenverarbeitung immer wichtiger wird.

(Bild: Crosser)
Auf welche Probleme treffen Sie bei Ihren Kunden bzw. in der Industrie allgemein? Welche Ziele verfolgen Ihre Kunden?
Kai Schwab: Bei unseren Kunden spielen zurzeit Kostensenkungen, organisatorische Herausforderungen wie Mitarbeitermangel und Innovationsdruck sowie technische Hürden in der Projektumsetzung eine tragende Rolle. Zunächst ein Satz zum Kostenthema. In einer Fabrik entstehen unglaublich viele Daten mit denen umgegangen werden muss. Gehen diese Datenmengen alle ungefiltert in die Cloud, entstehen sehr hohe Speicherkosten. Des Weiteren müssen Daten in die Cloud gelangen und dafür wird Bandbreite benötigt – das kostet ebenfalls Geld. Werden zusätzlich noch IoT-Services genutzt, entstehen weitere Kosten. Organisatorische Fragestellungen wären z.B. die Skalierbarkeit von Pilotprojekten. Auch fehlende IT-Ressourcen sind in diesem Zusammenhang ein wichtiges Thema, bei dem Edge Analytics helfen kann. Technische Aspekte wären etwa fehlende Bandbreiten oder zu hohe Latenzzeiten in der Cloud-Integration. Dazu kommen technische Anforderungen um OT-, IT- und Cloud-Daten zu konsolidieren und mit Kontext anzureichern. Diese Problemstellungen können Unternehmen mit Edge Analytics lösen.
Was ist Edge Analytics?
Schwab: Das Thema lässt sich u.a. drei Industrietypen zuordnen: Industrie 4.0, Maschinen im Feld /IIoT und Enterprise Integration. Die Edge definiert sich dabei als der Punkt, an dem die Daten entstehen. Das kann ein Sensor, eine Maschine, ein Gateway oder Industrie-PC sein. In aktuellen Projekten wird die Edge um die Endpunkte IT-Systeme (ERP, CRM, Datenbanken etc.) und die Cloud erweitert. Unter Analytics wird das Lesen, die Harmonisierung und die Transformation sowie die Anreicherung von Daten verstanden. Dies geht bis zu dem Punkt, an dem entschieden wird, ob die Daten in ein IT-System (ERP, CRM oder Datenbank etc.) oder eine Cloud übertragen oder direkt vor Ort, an der Edge, mit Hilfe eines KI-Modells verarbeitet werden.
Worin sehen Sie gängige Szenarien für Edge Analytics?
Schwab: Es geht bei den Edge-Analytics-Anwendungsfällen darum, Daten zu lesen, diese abzuspeichern und schließlich weiterzuleiten – einschließlich der Datenaggregation. Dadurch werden das Datenvolumen sowie die Anzahl der Transaktionen in die Cloud reduziert. Auch die Integration verschiedener Ebenen in der IT-Architektur ist denkbar, etwa wenn es darum geht ERP-Daten mitzuführen. Auch Maschine zu Maschine-Kommunikation ist ein spannender Anwendungsfall. Dabei geht es nicht nur darum, Maschinendaten zu erfassen, sondern Maschinen auch zu steuern bzw. Logik zu verteilen und KI-Modelle direkt an der Edge einzusetzen. Kamerabasierte Überwachung in der Produktion ist ein weiterer wichtiger Bereich, welcher zur Qualitätssicherung im Herstellungsprozess genutzt wird. Zusätzlich spielt das Thema Datensicherheit bei Unternehmen eine wichtige Rolle. Stellen Sie sich vor, Sie haben einen Lieferanten der Ihnen eine Maschine installiert und selbst Daten erfassen möchte. Dafür ist es wichtig festzulegen, welche Daten der Lieferant einsehen kann. Auf der anderen Seite möchten Maschinenbauer wiederum die Daten Ihrer Maschinen beim Kunden nutzen. Dies gilt es durch Edge Analytics zu steuern.
Was verbirgt sich hinter Crosser Cloud und Crosser Node?
Schwab: Die Crosser Node ist eine Software, welche nahe am Ort der Datenentstehung installiert ist. Sie ist hardware-agnostisch und wird in Containern ausgerollt. Die Software kann auch in der Cloud oder in einer virtuellen Maschine genutzt werden. Mit ihr wird Logik, also die Erhebung der Daten und deren weitere Verarbeitung, am Ort der Datenentstehung umgesetzt. Die Lösung ist modular aufgebaut und Anwender können aus einer Bibliothek bestehend aus Modulen die jeweilige Prozesslogik per Drag&Drop zusammensetzen. Die Konfiguration, das Testen, Verteilen und Überwachen erfolgt durch die Crosser Cloud. In die Crosser Cloud werden dabei keinerlei Transaktionsdaten übertragen. Ist die Konfiguration der Edge Node abgeschlossen, kann die Crosser Cloud von der Edge Node getrennt werden.
Gibt es darüber hinaus noch weitere technische Voraussetzungen?
Schwab: Überall dort wo Docker-Container oder Windows genutzt werden kann, kann die Crosser Edge Node eingesetzt werden. Darüber hinaus wird bei der Nutzung komplexer KI-Modelle mehr Rechenleistung an der Edge benötigt.
Mit ML-Ops bieten Sie die Möglichkeit, Machine Learning-Algorithmen einzubinden. Was verbirgt sich hinter dem Ansatz?
Schwab: Beim ML (Machine Learning) geht es darum, KI-Modelle zu trainieren. Dafür werden Daten in entsprechender Granularität und Qualität benötigt. Crosser bietet die Möglichkeit, die Daten vorzubereiten, um solche Modelle zu trainieren. Zusätzlich geht es auch um die Verteilung der Modelle: Ist das entsprechende ML-Modell vorhanden und muss auf Endpunkte verteilt werden, kann das natürlich aufwendig individuell pro Modell gemacht werden. Intelligenter ist es die Modelle zentral zu verwalten, zu verteilen und zu aktivieren. Dieser Mechanismus wird als ML-Ops bezeichnet und von Crosser bereitgestellt. Alternativ können Unternehmen auch KI-Werkzeuge anderer Hersteller mit entsprechenden Schnittstellen nutzen.
Wo sehen Sie die Vorteile von Edge Computing allgemein, und warum denken Sie wird der Edge-Ansatz auch in Zukunft relevant sein?
Schwab: Angesichts der aktuellen weltpolitischen Situation ist es wahrscheinlich, dass wir uns, was die Datenhoheit angeht, immer mehr abkapseln werden. Die zentrale Verarbeitung der Daten, möglichst vor Ort, wird wichtiger. Hat ein Unternehmen beispielsweise Standorte in den USA und China, stellt sich die Frage, wie diese Daten überhaupt verarbeitet werden dürfen. Es kann die Anforderung bestehen die Daten vor Ort zu betrachten und da bietet sich Edge Computing an.
Sie verfolgen mit Ihrer Lösung einen Low-Code-Ansatz. Warum dieser Ansatz, und wo sehen Sie Vor- bzw. Nachteile von Low Code/NoCode?
Schwab: Ein Vorteil von Low Code ist, dass im Normalfall kaum IT-Knowhow der Anwender notwendig ist. Zum anderen beobachten wir, dass es Unternehmen oft an IT-Ressourcen mangelt. Die Einbindung der Fachseite gemeinsam mit der IT ist damit ein entscheidender Erfolgsfaktor. Der Low-Code-Ansatz ist dafür perfekt geeignet. Beide Welten können zusammengeführt werden. Um darüber hinaus individuelles Coding zu ermöglichen, stellen wir bei Crosser deshalb Module bereit, bei denen Entwickler eigenen Programmiercode einbinden können. So können Unternehmen ihre individuell entwickelten Logiken integrieren und nach wie vor auch den etablierten DevOps-Prozess nutzen.
Wie sieht Ihre weitere Roadmap aus, speziell wenn es um die DACH-Region geht?
Schwab: Die Entwicklung unseres Partner Eco-Systems spielt eine zentrale Rolle. Alles selbst zu entwickeln ist bei den heutigen schnellen Veränderungen kaum mehr möglich. Es gibt Unternehmen am Markt, die versuchen, alles aus einer Hand anzubieten. Wir bei Crosser beobachten jedoch, dass dieses Vorgehen immer mehr auf Widerstand stößt. Deshalb kombinieren wir die Crosser Plattform flexibel mit unseren Hardware- und Servicedienstleistungspartnern. Was den Markt in der DACH-Region angeht, spielt das Thema Daten und deren Nutzung eine zentrale Rolle. Lange war es so, dass Unternehmen eine ‘Cloud-Only-Strategie’ verfolgt haben. Heute hingegen favorisieren Unternehmen immer mehr eine hybride Strategie, verfolgen also eine Cloud- Edge-Kombination. Darin sehe ich großes Potenzial für Crosser. Ein weiteres Feld sind Maschinenbauer, welche sich vom Hardwareanbieter hin zum Lösungsanbieter inkl. Software entwickeln wollen. Der vierte Bereich ist die Reduktion der Komplexität der Integration von Unternehmenssoftware. Dort brauchen Unternehmen einfache Lösungen um OT, IT und Cloud miteinander sprechen zu lassen. Da sehe ich in der Dach-Region eine Menge Potenzial.
Vielen Dank für das Gespräch!
Das könnte Sie auch interessieren

Werkzeugbahnen für Zerspanprozesse in CAM-Systemen zu planen erfordert Expertenwissen. Viele Parameter müssen bestimmt und geprüft werden, um die Bahnplanung Schritt für Schritt zu optimieren. Im Projekt CAMStylus arbeiten die Beteiligten daran, diese Aufgabe zu vereinfachen - per KI-gestützter Virtual-Reality-Umgebung.‣ weiterlesen

AappliedAI hat vier KI Use Cases identifiziert, die es dem produzierenden Gewerbe ermöglichen, ihre Effizienz und Produktivität zu steigern. Mit der Anwendung bewährter Technologien können sich die Investitionen bereits nach einem Jahr amortisieren.‣ weiterlesen

Hinter jedem erfolgreichen Start-up steht eine gute Idee. Bei RockFarm sind es gleich mehrere: Das Berliner Unternehmen baut nachhaltige Natursteinmauern aus CO2 bindendem Lavagestein. Oder besser gesagt, es lässt sie bauen - von einem Yaskawa-Cobot HC10DTP.‣ weiterlesen

In einer Studie von Techconsult in Zusammenarbeit mit Grandcentrix wurden 200 Unternehmen ab 250 Beschäftigten aller Branchen zum Thema ESG in ihren Unternehmen befragt. Die Studie hebt die zentrale Rolle der jüngsten CSR-Direktive der EU bei der Förderung von Transparenz und Nachhaltigkeit in Unternehmen hervor. Dabei beleuchtet sie die Fortschritte und Herausforderungen bei der Umsetzung von Umwelt-, Sozial- und Unternehmensführungskriterien (ESG) im Zusammenhang mit der Nutzung von IoT-Technologien.‣ weiterlesen

Mit über 2,2Mio.t verarbeitetem Schrott pro Jahr ist die Swiss Steel Group einer der größten Recyclingbetriebe Europas. Für seinen 'Green Steel', also Stahl aus recyceltem Material, arbeitet das Unternehmen an einem digitalen Zwilling des ankommenden Schrotts.‣ weiterlesen

Laut einer aktuellen Studie von Hitachi Vantara betrachten fast alle der dafür befragten Unternehmen GenAI als eine der Top-5-Prioritäten. Aber nur 44 Prozent haben umfassende Governance-Richtlinien eingeführt.‣ weiterlesen
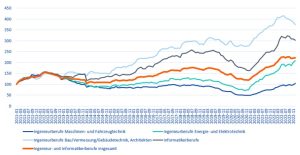
61 Prozent der Unternehmen in Deutschland wollen laut einer Bitkom-Befragung per Cloud interne Prozesse digitalisieren, vor einem Jahr waren es nur 45 Prozent. Mittelfristig wollen die Unternehmen mehr als 50 Prozent ihrer Anwendungen in die Cloud verlagern.‣ weiterlesen

Mit generativer KI erlebt 'Right Brain AI', also eine KI, die kreative Fähigkeiten der rechten menschlichen Gehirnhälfte nachahmt, derzeit einen rasanten Aufstieg. Dieser öffnet aber auch die Tür für einen breiteren Einsatz von eher analytischer 'Left Brain AI'. Das zeigt eine aktuelle Studie von Pegasystems.‣ weiterlesen
Um klima- und ressourcengerechtes Bauen voranzubringen, arbeiten Forschende der Bergischen Universität Wuppertal in ihrem Projekt TimberConnect an der Optimierung von digitalen Prozessen entlang der Lieferkette von Holzbauteilen. Ihr Ziel ist unter anderem, digitale Produktpässe zu erzeugen.‣ weiterlesen

Rund zwei Drittel der Erwerbstätigen in Deutschland verwenden ChatGPT und Co. zumindest testweise, 37 Prozent arbeiten regelmäßig mit KI-Anwendungen. Doch auch Cyberkriminelle machen sich vermehrt die Stärken künstlicher Intelligenz zunutze - mit weitreichenden Folgen.‣ weiterlesen

Erstmals seit der Energiekrise verzeichnet der Energieeffizienz-Index der deutschen Industrie mit allen drei Teilindizes (die Bedeutung, Produktivität und Investitionen betreffend) einen leichten Rückgang. Mögliche Gründe erkennt EEP-Institutsleiter Professor Alexander Sauer in der Unsicherheit und der drohenden Rezession, der dadurch getriebenen Prioritätenverschiebung und der Reduktion von Produktionskapazität.‣ weiterlesen
INDUSTRIE 4.0 & IIoT-MAGAZIN Leseprobe

Zeitschrift für Industrie 4.0, Internet of Things & Digitale Transformation


Schäden für deutsche Unternehmen durch Cyberangriffe nehmen zu
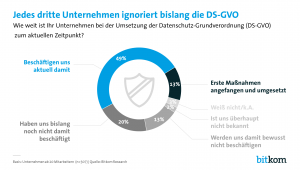
Mehr als jedes dritte Unternehmen wurde in den letzten zwei Jahren Opfer von Cyberkriminalität - am häufigsten durch Phishing, Attacken auf Cloud-Services oder Datenlecks. Dies geht aus einer Studie des Beratungsunternehmens KPMG hervor. Darin schätzt der Großteil der befragten Unternehmen das eigene Risiko als hoch oder sehr hoch ein.‣ weiterlesen

Das Gehirn austricksen: Haptik in der virtuellen Realität:
Wie kann man die virtuelle Realität (VR) haptisch, also durch den Tastsinn, erfahrbar machen? Der Saarbrücker Informatiker André Zenner ist in seiner Doktorarbeit der Antwort auf diese Frage ein großes Stück nähergekommen - indem er neue Geräte erfunden und die passende Software dazu entwickelt hat.‣ weiterlesen

Erste Hilfe bei Maschinenstörungen
Die Einführung generativer künstlicher Intelligenz ist oft mit Herausforderungen verbunden, etwa wenn es um den Datenschutz geht. Für die Industrie verspricht die Technologie jedoch Potenziale, sofern richtig eingesetzt. Die APPL-Firmengruppe nutzt GenAI beispielsweise, um Maschinenstörungen abzustellen.‣ weiterlesen

Mit Virtual Reality zur mehr Bedienerfreundlichkeit
Die Integration von Ergonomie in den Entwicklungsprozess von Maschinen und Arbeitsplätzen spielt eine entscheidende Rolle für die Kosteneffizienz und die Benutzerfreundlichkeit. Virtual Reality (VR) bietet einen modernen Ansatz, um frühzeitige Ergonomieuntersuchungen zu beschleunigen und zu verbessern. Die Integration von VR ermöglicht eine realistische Simulation menschlicher Bewegungen und vermeidet kostspielige spätere Anpassungen. Die Anwendung erfordert jedoch geeignete Hardware und Software sowie geschultes Personal.‣ weiterlesen

USA führend bei Digitalinnovationen
Die Innovationstätigkeit in Digitaltechnologien nimmt weiter an Fahrt auf. Und laut Deutschem Patent- und Markenamt dominieren die USA und China in diesen Bereichen. Die deutsche Bilanz ist zwiespältig.‣ weiterlesen