Projekt Direct State Transfer
Bosch-Forschungsteam macht DLT-Anwendungen skalierbar
![]() Nicht der Mensch bezahlt an der Kasse, sondern das Auto direkt an der Ladesäule. In einer Ökonomie der Dinge könnte dies Wirklichkeit werden. Genau daran forscht Bosch gemeinsam mit der TU Darmstadt.
Nicht der Mensch bezahlt an der Kasse, sondern das Auto direkt an der Ladesäule. In einer Ökonomie der Dinge könnte dies Wirklichkeit werden. Genau daran forscht Bosch gemeinsam mit der TU Darmstadt.
Gemeinsam mit verschiedenen Partnern forscht Bosch daran, dass sich vernetzte Dinge künftig in sicheren Ökosystemen selbstständig mit anderen vernetzten Dingen austauschen können und in der Lage sind, Verträge abzuschließen. In einer solchen ‘Ökonomie der Dinge‘ könnten Distributed-Ledger-Technologien (DLT), wie etwa die Blockchain, zu einer Schlüsseltechnologie werden. Prototypische Anwendungen gibt es bereits, für tragfähige Geschäftsmodelle fehlen jedoch noch die technischen Voraussetzungen, wenn es beispielsweise um Skalierbarkeit geht: „Skalierbarkeit ist eine der großen Herausforderungen bei DLT, weil im Idealfall zehntausende Transaktionen pro Sekunde in Echtzeit verarbeitet werden müssen. Das ist sehr speicher- und energieintensiv“, erklärt Daniel Kunz, Mitarbeiter im Projekt ‘Economy of Things‘ bei Bosch.
Direct State Transfer
Das Forschungsteam hat als Lösungsansatz das Open-Source-Projekt ‘Direct State Transfer‘ (DST) aufgesetzt, um das sogenannte Second-Layer-Protokoll ‘Perun‘ zu implementieren. DST ist unter der Apache-2.0-Lizenz auf GitHub veröffentlicht. Das Protokoll entstand aus einer gemeinsamen Forschungsarbeit der TU Darmstadt und der Universität Warschau. Die TU Darmstadt unterstützt das Bosch-Forschungsteam nun auch bei der Entwicklung der DST Smart Contracts. Wie Bosch mitteilt, hat das Projekt das Potenzial zu einer neuen Distributed-Ledger-Basistechnologie zu reifen, die das Versprechen einer dezentralen, sicheren und zugleich skalierbaren Lösung einlöst.
Zweite Schicht für die Blockchain
Second-Layer-Protokolle versuchen, die ressourcenintensiven Vorgänge zu umgehen, wenn Dinge mit Dingen dezentral Smart Contracts abwickeln. „Das heißt, wir haben auf ein Blockchain-System (First Layer) eine zweite Schicht (Second Layer) gebaut, die nur ganz selten mit der langsamen, dafür aber sehr komplexen und sehr sicheren Basisschicht spricht. Das Basissystem kann man sich wie einen Rahmenvertrag vorstellen, der immer gilt. Im Falle flexibler Anforderungen, bei denen beispielsweise nicht jede einzelne Transaktion dauerhaft gespeichert werden muss, können einzelne Prozesse auf einem zweiten System, dem Second Layer, laufen. So sind mehr und kosteneffizientere Transaktionen möglich“, erklärt Kunz.
Das könnte Sie auch interessieren

Werkzeugbahnen für Zerspanprozesse in CAM-Systemen zu planen erfordert Expertenwissen. Viele Parameter müssen bestimmt und geprüft werden, um die Bahnplanung Schritt für Schritt zu optimieren. Im Projekt CAMStylus arbeiten die Beteiligten daran, diese Aufgabe zu vereinfachen - per KI-gestützter Virtual-Reality-Umgebung.‣ weiterlesen

AappliedAI hat vier KI Use Cases identifiziert, die es dem produzierenden Gewerbe ermöglichen, ihre Effizienz und Produktivität zu steigern. Mit der Anwendung bewährter Technologien können sich die Investitionen bereits nach einem Jahr amortisieren.‣ weiterlesen

Hinter jedem erfolgreichen Start-up steht eine gute Idee. Bei RockFarm sind es gleich mehrere: Das Berliner Unternehmen baut nachhaltige Natursteinmauern aus CO2 bindendem Lavagestein. Oder besser gesagt, es lässt sie bauen - von einem Yaskawa-Cobot HC10DTP.‣ weiterlesen

In einer Studie von Techconsult in Zusammenarbeit mit Grandcentrix wurden 200 Unternehmen ab 250 Beschäftigten aller Branchen zum Thema ESG in ihren Unternehmen befragt. Die Studie hebt die zentrale Rolle der jüngsten CSR-Direktive der EU bei der Förderung von Transparenz und Nachhaltigkeit in Unternehmen hervor. Dabei beleuchtet sie die Fortschritte und Herausforderungen bei der Umsetzung von Umwelt-, Sozial- und Unternehmensführungskriterien (ESG) im Zusammenhang mit der Nutzung von IoT-Technologien.‣ weiterlesen

Mit über 2,2Mio.t verarbeitetem Schrott pro Jahr ist die Swiss Steel Group einer der größten Recyclingbetriebe Europas. Für seinen 'Green Steel', also Stahl aus recyceltem Material, arbeitet das Unternehmen an einem digitalen Zwilling des ankommenden Schrotts.‣ weiterlesen

Laut einer aktuellen Studie von Hitachi Vantara betrachten fast alle der dafür befragten Unternehmen GenAI als eine der Top-5-Prioritäten. Aber nur 44 Prozent haben umfassende Governance-Richtlinien eingeführt.‣ weiterlesen
61 Prozent der Unternehmen in Deutschland wollen laut einer Bitkom-Befragung per Cloud interne Prozesse digitalisieren, vor einem Jahr waren es nur 45 Prozent. Mittelfristig wollen die Unternehmen mehr als 50 Prozent ihrer Anwendungen in die Cloud verlagern.‣ weiterlesen

Mit generativer KI erlebt 'Right Brain AI', also eine KI, die kreative Fähigkeiten der rechten menschlichen Gehirnhälfte nachahmt, derzeit einen rasanten Aufstieg. Dieser öffnet aber auch die Tür für einen breiteren Einsatz von eher analytischer 'Left Brain AI'. Das zeigt eine aktuelle Studie von Pegasystems.‣ weiterlesen
Um klima- und ressourcengerechtes Bauen voranzubringen, arbeiten Forschende der Bergischen Universität Wuppertal in ihrem Projekt TimberConnect an der Optimierung von digitalen Prozessen entlang der Lieferkette von Holzbauteilen. Ihr Ziel ist unter anderem, digitale Produktpässe zu erzeugen.‣ weiterlesen

Rund zwei Drittel der Erwerbstätigen in Deutschland verwenden ChatGPT und Co. zumindest testweise, 37 Prozent arbeiten regelmäßig mit KI-Anwendungen. Doch auch Cyberkriminelle machen sich vermehrt die Stärken künstlicher Intelligenz zunutze - mit weitreichenden Folgen.‣ weiterlesen

Erstmals seit der Energiekrise verzeichnet der Energieeffizienz-Index der deutschen Industrie mit allen drei Teilindizes (die Bedeutung, Produktivität und Investitionen betreffend) einen leichten Rückgang. Mögliche Gründe erkennt EEP-Institutsleiter Professor Alexander Sauer in der Unsicherheit und der drohenden Rezession, der dadurch getriebenen Prioritätenverschiebung und der Reduktion von Produktionskapazität.‣ weiterlesen
INDUSTRIE 4.0 & IIoT-MAGAZIN Leseprobe

Zeitschrift für Industrie 4.0, Internet of Things & Digitale Transformation


Schäden für deutsche Unternehmen durch Cyberangriffe nehmen zu
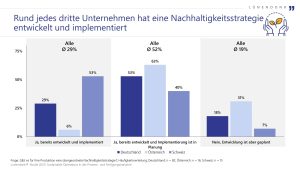
Mehr als jedes dritte Unternehmen wurde in den letzten zwei Jahren Opfer von Cyberkriminalität - am häufigsten durch Phishing, Attacken auf Cloud-Services oder Datenlecks. Dies geht aus einer Studie des Beratungsunternehmens KPMG hervor. Darin schätzt der Großteil der befragten Unternehmen das eigene Risiko als hoch oder sehr hoch ein.‣ weiterlesen

Das Gehirn austricksen: Haptik in der virtuellen Realität:
Wie kann man die virtuelle Realität (VR) haptisch, also durch den Tastsinn, erfahrbar machen? Der Saarbrücker Informatiker André Zenner ist in seiner Doktorarbeit der Antwort auf diese Frage ein großes Stück nähergekommen - indem er neue Geräte erfunden und die passende Software dazu entwickelt hat.‣ weiterlesen

Erste Hilfe bei Maschinenstörungen
Die Einführung generativer künstlicher Intelligenz ist oft mit Herausforderungen verbunden, etwa wenn es um den Datenschutz geht. Für die Industrie verspricht die Technologie jedoch Potenziale, sofern richtig eingesetzt. Die APPL-Firmengruppe nutzt GenAI beispielsweise, um Maschinenstörungen abzustellen.‣ weiterlesen

Mit Virtual Reality zur mehr Bedienerfreundlichkeit
Die Integration von Ergonomie in den Entwicklungsprozess von Maschinen und Arbeitsplätzen spielt eine entscheidende Rolle für die Kosteneffizienz und die Benutzerfreundlichkeit. Virtual Reality (VR) bietet einen modernen Ansatz, um frühzeitige Ergonomieuntersuchungen zu beschleunigen und zu verbessern. Die Integration von VR ermöglicht eine realistische Simulation menschlicher Bewegungen und vermeidet kostspielige spätere Anpassungen. Die Anwendung erfordert jedoch geeignete Hardware und Software sowie geschultes Personal.‣ weiterlesen

USA führend bei Digitalinnovationen
Die Innovationstätigkeit in Digitaltechnologien nimmt weiter an Fahrt auf. Und laut Deutschem Patent- und Markenamt dominieren die USA und China in diesen Bereichen. Die deutsche Bilanz ist zwiespältig.‣ weiterlesen