KI-Projektierung richtig aufsetzen
Schnittmengen der KI
Der häufig in diesem Zusammenhang verwendete Begriff ‘künstliche Intelligenz’ ist nicht allgemeingültig definiert, sondern beschreibt lediglich eine Hard- oder Software, die in einer gewissen Art und Weise menschliches Verhalten imitiert. Ob dieses Verhalten auf klassisch programmierten Wenn-dann-Regeln basiert oder auf komplexeren Modellierungen, macht dabei keinen Unterschied. Eine Teilmenge der künstlichen Intelligenz ist das datenbasierte maschinelle Lernen, wozu auch Deep Learning mit tiefschichtigen neuronalen Netzen zählt. Es gliedert sich in drei Kategorien:
- • Supervised Learning (beaufsichtigtes Lernen) – Darunter fallen Input-Output-Paare, z.B. die Nutzungsart einer Maschine (Input) und die dazugehörige Temperaturentwicklung einer Maschinenkomponente (Output). Die KI beobachtet über einen längeren Zeitraum, wie Nutzungsart und Temperaturentwicklung zusammenhängen, und ist anschließend in der Lage, Temperaturentwicklungen vorherzusagen und darauf basierend auffällige Temperaturabweichungen zu erkennen.
- • Unsupervised Learning (unbeaufsichtigtes Lernen) – Hier untersucht eine KI ohne Vorwissen einen Datensatz dahingehend, ob Zusammenhänge erkennbar sind. Eine solche KI könnte beispielsweise einen bunt gemischten Haufen aus Dreiecken, Vierecken und Kreisen in verschiedene Cluster sortieren (Anzahl der Ecken, Größe, Farbe etc.). Spannend ist eine KI dieser Art für Daten, die ein Mensch aufgrund ihrer Komplexität nicht mehr analysieren kann.
- • Reinforcement Learning (bestärkendes Lernen) – Das KI-Modell trainiert sich selbst und wird im Erfolgsfall belohnt. Eine selbstlernende KI für das Spiel ‘Vier gewinnt’ probiert unterschiedliche Vorgehensweisen und lernt aus Gewinnen und Verlieren. Das funktioniert im Zusammenspiel mit einem Menschen und bei manchen Konstellationen auch im Training gegen sich selbst. Auf diese Weise kann KI beispielsweise die Stromaufnahme von Maschinenparks optimieren.
Data-Science-Projektablauf
Doch wie funktioniert in der Praxis der Weg vom Datenhaufen zur KI? “Schritt für Schritt”, lautet die Antwort von Frank Müller, “obgleich das große Ziel stets die Richtung vorgibt.” Ein Ziel könnte beispielsweise eine Software sein, die den Ausfall von Gerätekomponenten vorhersagt, automatisiert Ersatzteile bestellt und den Technikereinsatz koordiniert. Im ersten Schritt beschäftigen sich die Datenwissenschaftler mit einer rein deskriptiven Bestandsaufnahme der verfügbaren Daten. Zusammenhänge zwischen Daten und eine Analyse, warum ein Ereignis eingetreten ist, entstehen im zweiten Schritt. Sobald die Ursachen bekannt sind, können die Datenwissenschaftler Modelle erstellen, die im dritten Schritt Vorhersagen ermöglichen. Darauf baut Schritt vier auf, der Handlungsempfehlungen anhand der Vorhersage ermöglicht. Diese Empfehlungen lassen sich im fünften Schritt automatisieren. Die Software bestellt beispielsweise das Ersatzteil und informiert den Service-Techniker. Ebenso ist auch eine automatisierte Abschätzung dahingehend möglich, ob der Techniker kurzfristig eine Wartung durchführen muss oder ob es ausreicht, wenn er die Reparatur im Zuge einer ohnehin geplanten Wartung in zwei Wochen durchführt. “Das Schöne an Data-Science-Projekten ist”, so Frank Müller, “dass wir jederzeit in Projekte einsteigen und sie anschieben können – ganz gleich auf welcher Stufe sie sich derzeit befinden.” Ein Pluspunkt, den sich vor Jahrzehnten auch die US Navy in der Zusammenarbeit mit Adam Wald zu eigen machte. Die Militärexperten waren damals auf eine kognitive Verzerrung hereingefallen, die Statistiker heute als Survivorship Bias beziehungsweise Überlebenden-Verzerrung bezeichnen. Auch heute ist sie allgegenwärtig, beispielsweise wenn uns die Existenz alter Gebäude glauben lässt, früher sei die Bauqualität vergleichsweise höher gewesen. Tatsächlich handelt es sich jedoch lediglich um qualitativ oder ästhetisch hochwertige Gebäude, die seltener abgerissen und zugleich intensiver gepflegt werden als andere längst verschwundene Gebäude aus dieser Zeit.
Das könnte Sie auch interessieren

Für das aktuelle Allianz Risk Barometer wurden 3000 Risikoexperten befragt. Das Ergebnis: Als größte Risiken nennen die Teilnehmer Datenpannen, Angriffe auf kritische Infrastruktur oder Vermögenswerte und vermehrte Ransomware-Attacken. Anders als weltweit schafft es der Fachkräftemangel in Deutschland auf Platz 4.‣ weiterlesen

In Potsdam laufen die Vorbereitungen für eine vollständig digitale Universität. Die beiden Initiatoren Mike Friedrichsen und Christoph Meinel wollen damit dem IT-Fachkräftemangel entgegenwirken.‣ weiterlesen
@Grundschrift_NH:Nvidias Omniverse lässt sich künftig über T-Systems beziehen. Die Plattform der Grafik-Spezialisten ermöglicht es, komplexe 3D-Pipelines und Universal Scene Description (OpenUSD)-Anwendungen für Industrieanwendungen zu entwickeln und anzubinden. So können Unternehmen ihre 3D-Werkzeuge und -Daten mit dem Open-USD-Standard vereinheitlichen, um Teams über ihre PCs in bis zu fotorealistischen Visualisierungen und Simulationen zusammenzubringen. ‣ weiterlesen
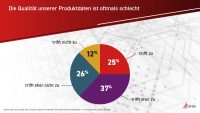
Sechs von zehn Unternehmen sind mit der Qualität ihrer Produktdaten unzufrieden. Das zeigt eine europaweite Befragung des Softwareherstellers Aras unter mehr als 440 Entscheidern. Zudem ergab die Untersuchung, dass Informationen, die eigentlich abteilungsübergreifend zugänglich sein sollten, oft ungenutzt in abgeschotteten Unternehmensbereichen liegen.‣ weiterlesen

Der Anteil der Unternehmen, die KI einsetzen, ist binnen eines Jahres von 9 auf 15 Prozent gestiegen. Das ist das Ergebnis einer Bitkom-Befragung unter 605 Unternehmen. Zwei Drittel von ihnen sehen KI als wichtigste Zukunftstechnologie.‣ weiterlesen

Derzeit erleben wir multiple Krisen - neben zunehmenden geopolitischen Spannungen entwickelt sich die Erderwärmung zu einer immer größeren Herausforderung. Das Umweltbundesamt rechnet bis Ende des 21. Jahrhunderts mit einer Erhöhung der mittleren Erdtemperatur um bis zu 5,7 Grad Celsius, sofern nicht kurzfristig eine massive Reduktion der CO2-Emissionen erfolgt. Wie der CO2-Fußabdruck dabei unterstützen kann, beschreibt ein Beitrag des Beratungsunternehmens Aflexio.‣ weiterlesen
Mit bestehenden Geothermiebohrungen im Oberrheingraben könnte zuverlässig Lithium gefördert werden. Das zeigen aktuelle Datenanalysen von Forschenden des Karlsruher Instituts für Technologie (KIT). Frisches Tiefenwasser sorgt über mehrere Jahrzehnte für Nachschub. ‣ weiterlesen
Mit einem messdatengestützten Retrofit-System können ältere Windkraftanlagen länger laufen. Im von Bachmann Monitoring und P. E. Concepts entwickelten System fließen erfasste Last- und Eigenfrequenzdaten in die Lebensdauer-Berechnung von Komponenten ein. Anhand dieser Daten lässt sich eine realistischere Restnutzungsdauer errechnen, um den rentablen Weiterbetrieb zu ermöglichen. ‣ weiterlesen
INDUSTRIE 4.0 & IIoT-MAGAZIN Leseprobe

Zeitschrift für Industrie 4.0, Internet of Things & Digitale Transformation