Big Data: Wie Daten sprechen lernen
Knoten und logische Regeln
Entscheidungsb?ume sind die logische Folge einer Prozessanalyse mit Parallelkoordinaten, in dem sie daraus logische Entscheidungsdiagramme generieren. Daraus folgt, dass diese Algorithmen nur dann erfolgreich eingesetzt werden, wenn die Resultate der Prozessanalyse mit Parallelkoordinaten eindeutig ausfallen. Die Komplexit?t der Regeln ist bei Entscheidungsb?umen unbeschr?nkt. Bei bin?ren Entscheidungsb?umen kann jede Regel nur einen von zwei Werte annehmen. Alle Entscheidungsb?ume lassen sich immer in bin?re Entscheidungsb?ume ?berf?hren. Entscheidungsb?ume k?nnen entweder von Experten manuell erstellt oder mithilfe von Techniken des maschinellen Lernens automatisch aus Beispieldatens?tzen generiert werden. F?r diese Induktion gibt es mehrere konkurrierende Algorithmen. Stark miteinander korrelierende Eingangsvariablen k?nnen redundante Informationen enthalten, das hei?t eine der beiden Variablen w?re dann zweckm??igerweise von der weiteren Datenanalyse auszunehmen. Sollen stark korrelierende Eingangsmerkmale untersucht werden, kann die Korrelation durch Berechnungen wie das Verh?ltnis oder die Differenz der Variablen aufgehoben und die Datenanalyse so erleichtert werden. Das statistische Ma? der Korrelation ist nicht eindeutig interpretierbar, weil es linear und eindimensional ist und somit nur einen sehr begrenzten Einblick in tats?chliche Zusammenh?nge erm?glicht, die ja zum Beispiel nichtlinear sein k?nnen. Es gibt aber gute erste Hinweise auf bestehende Zusammenh?nge. Gibt es eine hohe Korrelation zwischen Ein- und Ausg?ngen, ist es eventuell sinnvoll, die Differenz zwischen der Zielgr??e und dem Vielfachen der Einflussgr??e zu modellieren. Mittels der Assoziationsanalyse kann das gemeinsame h?ufige Vorkommen kategorialer oder bin?rer Variablen untersucht werden. Dazu eignen sich grunds?tzlich einfache Verfahren wie Assoziationsregeln, die ausgehend von einer Kombination von bin?ren (beschreibenden) Variablen eine Kombination von Zielvariablen mit einem vorgegeben Mindestsupport und einer gewissen Konfidenz vorhersagen. Dabei ist die Konfidenz durch den relativen Anteil der Zielvariablen in der Subgruppe der Datenmenge gegeben, der Mindestsupport durch deren Gr??e, die durch die beschreibenden Variablen definiert wird. Im Vergleich zu Assoziationsregeln ist die Subgruppenentdeckung eine m?chtigere Methode, um auch mit analogen Variablen, also kontinuierlichen Messgr??en umgehen zu k?nnen. Bei der Subgruppenentdeckung geht es darum, m?glichst interessante Subgruppen hinsichtlich eines bestimmten Zielkonzepts zu identifizieren, beispielsweise f?r eine analoge Messgr??e Ausschussrate als Zielvariable. Grunds?tzlich wird meist auf m?glichst gro?e Subgruppen mit einer m?glichst hohen Abweichung dieser Zielvariablen im Vergleich zur Gesamtdatenmenge abgezielt. Im bin?ren Fall wird der Anteil der Zielvariablen in der Subgruppe betrachtet, die durch die beschreibenden Variablen (zum Beispiel Parameter Druck und Temperatur) gegeben ist. Diese Beschreibung kann als Kondition einer Regel aufgefasst werden, die Konklusion der Regel als das Zielkonzept.
Komplexe Zusammenh?nge
Die Interessantheit wird durch eine Qualit?tsfunktion definiert. Bei analogen Zielgr??en kann einfach der Durchschnitt ?ber die Datenmenge der Subgruppe gebildet werden, um m?glichst auff?llige Subgruppen zu identifizieren. Assoziations- und Abweichungsanalyse kann damit als eine Technik zur initialen Untersuchung komplexerer Zusammenh?nge dienen. Diese werden als leicht interpretierbare Regeln pr?sentiert. Im Vergleich zu Entscheidungsb?umen werden diskriminierende Regeln f?r ein Zielkonzept bestimmt, die lokal f?r sich stehen, und auch losgel?st von den anderen Regeln betrachtet werden k?nnen. Damit liegt der Vorteil der Subgruppenentdeckung auch darin, komplexe Probleme einer ?bersichtlichen Menge von Subgruppen abzubilden, die verst?ndlich sind, um Prozesskenntnis generieren. Subgruppenentdeckung l?sst sich beispielsweise auch als statistischer Plausibilit?tsfilter nutzen, um lokale Abweichungen zu entdecken. Eine wichtige Anwendung in technischen Produktionsprozessen ist beispielsweise auch die Fehleranalyse, in der Einflussgr??en f?r Zielvariablen wie Ausschuss- oder Reparaturrate mittels Subgruppenentdeckung analysiert werden. Die Hauptkomponentenanalyse (PCA) ist ein mathematisches Verfahren der multivariaten Statistik, bei dem vieldimensionale Daten in einem gedachten Koordinatensystem so gedreht werden, dass f?r jede Achse eine m?glichst hohe Varianz erreicht wird. Nach dieser Rotation entsprechen die Achsen nicht mehr bestimmten physikalischen Gr??en, sondern jeweils einer Linearkombination mehrerer Variablen. Die Linearkombinationen mit der h?chsten Varianz werden als Hauptkomponenten bezeichnet.
Variablen reduzieren
Durch die PCA kann die Zahl von Variablen reduziert werden, weil eine geringe Anzahl von Komponenten meist ausreicht, um die vieldimensionalen Daten mit ihrer gesamten Varianz abzubilden. Das Ergebnis einer PCA ist nicht immer klar interpretierbar. Wenn physikalisch ?hnliche oder miteinander zusammenh?ngende Gr??en zu einer Hauptkomponente beitragen, kann man diese mit einem sprechenden Namen bezeichnen (zum Beispiel ‘Gr??e’, wenn die variablen L?nge, Breite und H?he eines Werkst?cks am meisten zu einer Komponente beitragen). Kann eine solche Bezeichnung nicht gefunden werden, bleibt die Komponente abstrakt und die Interpretation sowohl der PCA an sich, als auch eventuell nachfolgender Datenanalysen ist erschwert. Mutual Information (auch Transinformation, Synentropie oder gegenseitige Information) ist eine Gr??e aus der Informationstheorie, die im Zusammenhang von Big-Data-Projekten angibt, wie viel Information eine (Eingangs-)Variable ?ber eine andere (Ausgangs-) Variable enth?lt. Sie ist maximal, wenn eine der Variablen sich aus der jeweils anderen berechnen l?sst. Sie ist minimal, wenn die untersuchten Variablen statistisch unabh?ngig sind. Der Begriff Entropie aus der shannonschen Theorie ist eine Ma?zahl f?r die Informationsdichte oder den Informationsgehalt von zu untersuchenden Datenreihen. Die Informationsdichte berechnet sich aus der Wahrscheinlichkeitsverteilung. Eine maximale Entropie zeichnet sich durch eine gleichm??ige Verteilung einer Datenfolge ?ber den Wertebereich aus. Datenfolgen mit einer maximalen Entropie lassen sich nicht verdichten oder komprimieren, da zur Datenverdichtung immer Redundanzen notwendig sind. Mit einer Entropieanalyse k?nnen irrelevante Variablen identifiziert und entfernt werden.
Das könnte Sie auch interessieren

Die Industrie arbeitet daran, die Barrieren zwischen IT und OT abzubauen. So können Unternehmen ihre Produktion effizienter und innovativer gestalten und im immer härter werdenden globalen Wettbewerb bestehen. Francis Chow von Red Hat erklärt, welche Rolle Open-Source-Technologien dabei spielen.‣ weiterlesen

3 Prozent der großen Industrieunternehmen setzen GenAI bereits großflächig ein, und rund ein Viertel hat erste Pilotprojekte gestartet. Laut einer Untersuchung der Unternehmensberatung McKinsey kann die Mehrheit der Unternehmen den Mehrwert der Technologie für den Unternehmenserfolg bislang aber noch nicht beziffern.‣ weiterlesen
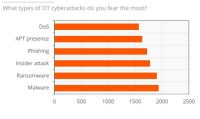
Ein Bericht von ABI Research und Palo Alto Networks über den Stand der OT-Sicherheit zeigt, dass im vergangenen Jahr eines von vier Industrieunternehmen seinen Betrieb aufgrund eines Cyberangriffs vorübergehend stilllegen musste. Die Komplexität beim Einsatz von OT-Sicherheitslösungen stellt für die Befragten das größte Hindernis dar.‣ weiterlesen

Für dauerhafte Wettbewerbsfähigkeit müssen deutsche Hersteller angesichts weiterhin drohender Rezession und hoher Energiekosten die nächste Stufe der Digitalisierung erreichen. Die Mehrheit der Unternehmen bereitet sich in diesem Zug auf Smart Manufacturing vor, wie eine von Statista durchgeführte und Avanade beauftragte Studie zeigt.‣ weiterlesen

Vom 22. bis zum 26. April wird Hannover zum Schaufenster für die Industrie. Neben künstlicher Intelligenz sollen insbesondere Produkte und Services für eine nachhaltigere Industrie im Fokus stehen.‣ weiterlesen

Eine Umfrage von Hewlett Packard Enterprise (HPE) unter 400 Führungskräften in Industrie-Unternehmen in Deutschland zeigt, dass zwei Drittel der Befragten den Data Act als Chance wahrnehmen. Der Data Act stieß unter anderem bei Branchenverbänden auf Kritik.‣ weiterlesen

Mit der Do-it-yourself-Automatisierung sollen Unternehmen ihre Automatisierungskonzepte selbst gestalten können. Die Komponenten dafür werden über eine Plattform bereitgestellt. Etienne Lacroix, CEO der DIY-Plattform Vention erklärt das Konzept.‣ weiterlesen

Fraunhofer-Forschende haben für Fahrer und Fahrerinnen von Baumaschinen einen Helm mit integriertem Beschleunigungssensor entwickelt. Die Helm-Sensorik misst die Vibrationen der Baumaschinen. Die Sensorsignale werden analysiert, eine Software zeigt die Belastung für den Menschen an.‣ weiterlesen

Deutsche Unternehmen nehmen eine zunehmende Bedrohung durch Cyber-Angriffe wahr. Das zeigt eine aktuelle Umfrage vom Markt- und Meinungsforschungsinstitut YouGov im Auftrag von 1&1 Versatel, an der mehr als 1.000 Unternehmensentscheider teilnahmen.‣ weiterlesen

Carbon Management-Technologien stehen im Fokus, um CO2-Emissionen zu reduzieren und zu managen. Die Rolle des Maschinenbaus und mögliche Entwicklungspfade betrachtet eine neue Studie des VDMA Competence Center Future Business.‣ weiterlesen

Rund 2.700 Aussteller aus mehr als 50 Ländern werden vom 10. bis 14. Juni zur Achema in Frankfurt erwartet. Mit mehr als 1.000 Rednern setzt das begleitende Kongress- und Bühnenprogramm darüber hinaus Impulse für eine erfolgreiche Transformation der Prozessindustrie. An allen fünf Messetagen sollen zudem Angebote für den Nachwuchs zur Zukunftssicherung der Branche beitragen.‣ weiterlesen
INDUSTRIE 4.0 & IIoT-MAGAZIN Leseprobe

Zeitschrift für Industrie 4.0, Internet of Things & Digitale Transformation